
Author:
(1) Mingda Chen.
Table of Links
-
3.1 Improving Language Representation Learning via Sentence Ordering Prediction
-
3.2 Improving In-Context Few-Shot Learning via Self-Supervised Training
-
4.2 Learning Discourse-Aware Sentence Representations from Document Structures
-
5 DISENTANGLING LATENT REPRESENTATIONS FOR INTERPRETABILITY AND CONTROLLABILITY
-
5.1 Disentangling Semantics and Syntax in Sentence Representations
-
5.2 Controllable Paraphrase Generation with a Syntactic Exemplar
6.2 Long-Form Text Summarization
6.2.1 Introduction
Abstractive summarization aims to produce a summary that concisely expresses key points of the input document rather than merely extracting pieces of it. Existing datasets are constructed from various domains, such as news (Sandhaus, 2008; Hermann et al., 2015; Rush et al., 2015; Narayan et al., 2018; Grusky et al., 2018), online forums (Volske et al. ¨ , 2017), meeting dialogues (Janin et al., 2003; Carletta et al., 2005), and webpages (Chen et al., 2020c). However, few datasets exist for abstractive summarization of narrative text, which focuses on entities and dialogue among entities, with plot details often communicated indirectly via dialogue. In this work, we build SUMMSCREEN, an abstractive summarization dataset combining TV series transcripts and episode recaps. Fig. 6.2 shows an example from SUMMSCREEN.
Several aspects of SUMMSCREEN make it a challenging testbed for abstractive summarization. First, the relationship between character dialogue and plot details is not straightforward. Plot events are often expressed indirectly in dialogue, and dialogue contains other information that is not directly relevant to the plot, such as character development and humor. Also, a typical episode has multiple subplots that proceed in parallel, with consecutive scenes often describing different subplots. Solving SUMMSCREEN requires drawing information from utterances across a wide range of the input and integrating the information to form concise plot descriptions. Moreover, since actual TV episodes ground their scripts with audio-visual accompaniment, many details may be omitted from the transcript itself. This omission of details and the other challenging aspects mentioned above have inspired research into other NLP tasks on TV show transcripts, such as entity tracking (Chen and Choi, 2016; Choi and Chen, 2018) and coreference resolution (Chen et al., 2017; Zhou and Choi, 2018)
Another prominent characteristic of TV series transcripts is their focus on characters. To reflect this aspect, we propose two entity-centric metrics to evaluate the quality of generated plot summaries. One is based on bags of characters, which measures the overlap of the characters that appear in both the generated and reference

recaps. The other metric measures character relations: the overlap of cooccurrences of character pairs in generations and recaps.
We empirically evaluate several types of methods on SUMMSCREEN. We consider nearest neighbor models, which look up similar transcripts or recaps, neural abstractive summarization models, and hybrid models, which use the nearest neighbor models as content selectors followed by abstractive summarization. Oracle extractive approaches outperform all models on all the automatic metrics. These results suggest that the benchmarked methods are unable to fully exploit the input transcripts and that improving content selection may be a promising research direction.
Human evaluations show that our non-oracle hybrid models are competitive with their oracle counterparts in terms of generating faithful plot events. Hybrid models may be promising approaches for future research. Qualitative analysis shows that neural models tend to generate generic summaries, hybrid models can benefit from better content selection, and hybrid models sometimes generate unfaithful details.
6.2.2 Related Work
There has been prior work on extractive screenplay summarization (Gorinski and Lapata, 2015; Papalampidi et al., 2020), and analyzing crime drama (Frermann et al., 2018). The majority of TV show transcripts are dialogues, relating our work to prior work on dialogue and meeting summarization. Relevant datasets have been studied for medical dialogues (Joshi et al., 2020a; Krishna et al., 2021b), chitchat (SAMSum; Gliwa et al., 2019), podcasts (Clifton et al., 2020), meetings (AMI; Carletta et al., 2005; ICSI; Janin et al., 2003; QMSum; Zhong et al., 2021a), livestreams (StreamHover; Cho et al., 2021), online forums (ForumSum; Khalman et al., 2021) and news interviews (MediaSum; Zhu et al., 2021).
Recently there have been efforts on adapting resources for TV shows for different tasks, including question answering (Ma et al., 2018a; Yang and Choi, 2019), speaker identification (Ma et al., 2017), sarcasm detection (Joshi et al., 2016), emotion detection (Zahiri and Choi, 2017; Hsu and Ku, 2018), character relation extraction (Yu et al., 2020), and story generation (Chen and Gimpel, 2021).
6.2.3 SUMMSCREEN
An instance in SUMMSCREEN contains a transcript from TV series and its corresponding recap. The transcripts consist of dialogue utterances with speaker names, and descriptions of scenes or character actions. The recaps are human-written summaries of the corresponding transcripts. Fig. 6.2 shows an example in SUMMSCREEN from the TV show “The Big Bang Theory”. The transcript documents a dialogue involving four characters (Sheldon, Leonard, Penny, and Amy) about playing a board game, and the recap summarizes the dialogue into sentences.
Dataset Construction. We use two sources to construct SUMMSCREEN: The TV MegaSite, Inc. (TMS)[11] and ForeverDreaming (FD),[12] both of which provide community-contributed transcripts. As FD does not provide recaps, we obtain recaps of FD shows from Wikipedia and TVMaze.[13] To ensure dataset quality of SUMMSCREEN, we filter out instances based on two criteria. First, the overlap ratio of TV show characters appearing in the recap and its transcript should be higher than 85%. We use this criterion to ensure that the alignments between recaps and transcripts are correct. Second, the number of transcript lines that have speaker information (“character utterances”) should be larger than 100. We use this criterion to eliminate transcripts that are essentially subtitles, i.e., utterances without speaker
information. In practice, for each transcript line, if a colon symbol appears in the first 8 tokens and there exists at least one character name in front of the colon symbol, we will count it as a character utterance. We note that FD and TMS do not have overlapping TV series.
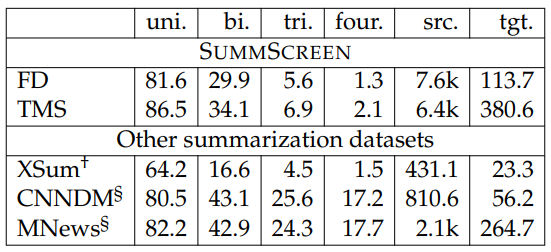
In Table 6.12, we compute n-gram overlap ratios between recaps and transcripts for measuring the abstractiveness of SUMMSCREEN. From the results, We find that despite SUMMSCREEN has longer summaries, its fraction of overlapping four-gram is comparable to XSum (Narayan et al., 2018) which is known for abstractiveness, suggesting that SUMMSCREEN favors abstractive approaches.
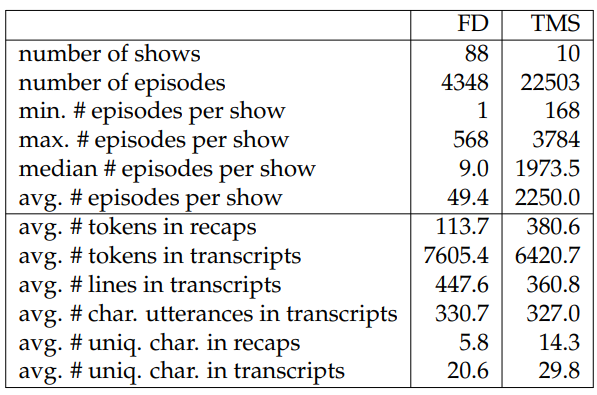
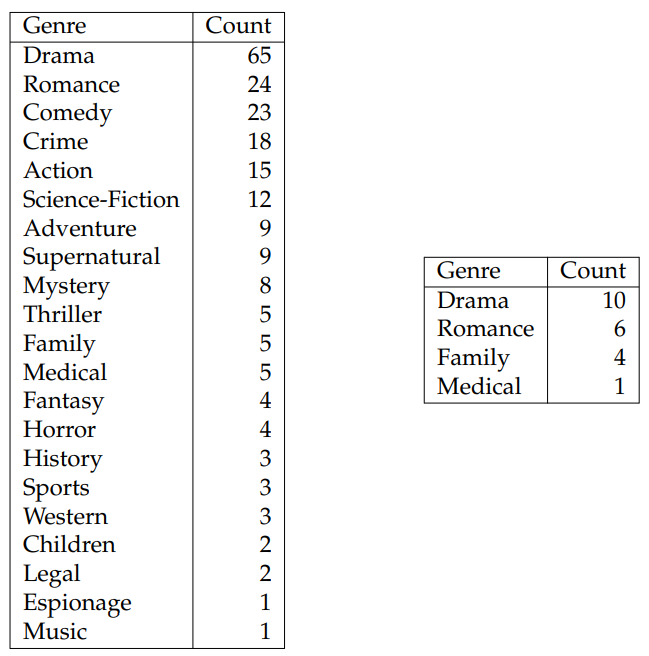
Table 6.13 shows data statistics and Fig. 6.3 shows the genres of the TV shows from the two sources.[14] When computing the number of unique characters in TV shows, we first collect the character names from TVMaze and the named entities[15] preceding the colon symbols in transcripts. We then perform string matching to obtain numbers of TV show characters in recaps and transcripts. From these two tables, we observe that FD and TMS are different in many aspects. First, FD covers more diverse genres than TMS. This is partly due to the fact that TV shows from TMS are soap operas. Second, transcripts from FD are longer, which is caused by the fact that the transcripts from FD tend to have more descriptions about environments or character actions, whereas the ones from TMS are mostly made up of dialogue (see Table 6.13). Third, recaps from FD are shorter whereas recaps from TMS seek
to cover more details. Fourth, writing styles are more diverse in FD than those in TMS. In light of these differences, we treat FD and TMS as different datasets in the following experiments.
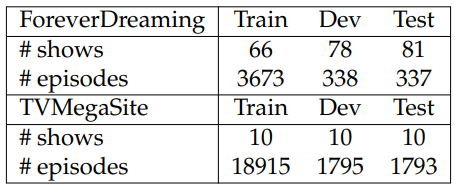
We create train/dev/test splits for FD and TMS by ensuring the ratio to be roughly 10:1:1, and filter out instances in the dev/test splits if the reference texts are shorter than 30 word tokens. The statistics of the splits are shown in Table 6.14.
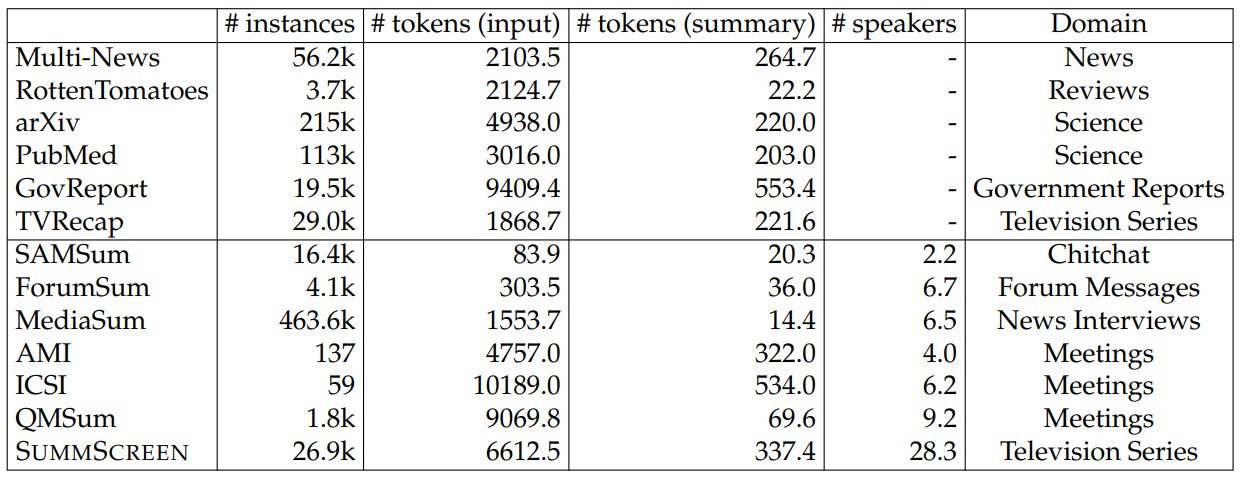
Dataset Comparison. We compare SUMMSCREEN to other abstractive dialogue summarization datasets in Table 6.15. SUMMSCREEN differs from other datasets in several ways:
-
Compared to recently proposed large-scale dialogue summarization datasets (i.e., SAMsum and MediaSUM), SUMMSCREEN has longer source inputs.
-
Compared to other dialogue summarization datasets, SUMMSCREEN has larger numbers of speakers per instance. The TV series genre focuses on narrative, which is typically entity-centric and can include multiple parallel subplots in a single episode.
-
Compared to AMI, ICSI and QMSum, which are long-input meeting summarization datasets, SUMMSCREEN has far more instances.
-
Unlike most of the other datasets, SUMMSCREEN contains many episodes of a single show (e.g., more than 3k episodes for TMS). This episodic structure could be used to model character arcs, the evolution of character personality traits and character relationships over episodes, among others.
Properties (1) and (2) above make extracting information from transcripts more challenging than other datasets. The third property means that SUMMSCREEN is large enough to train and evaluate neural methods.
The Spotify Podcast Dataset (Clifton et al., 2020) and StreamHover (Cho et al., 2021) are similar to SUMMSCREEN in that they contain transcribed speech and summaries. However, the transcriptions are obtained automatically and therefore contain errors.[16] The datasets therefore involve speech processing (or at least handling speech recognition errors) compared to SUMMSCREEN, which has human-written transcripts.
Since MediaSum is constructed from news transcripts, it is the most similar dataset in Table 6.15 to SUMMSCREEN. However, the summaries in MediaSum are twenty times shorter than those in SUMMSCREEN, and the average number of speakers per instance is only a quarter of that in SUMMSCREEN. Furthermore, our results in Section 6.2.5 indicate that our dataset is much harder than MediaSum as the pretrained models perform worse on our dataset than on MediaSum according to automatic metrics.
Dataset Challenges. We qualitatively analyze the challenging aspects of SUMMSCREEN. Since the transcripts focus on dialogue among characters, along with limited descriptions of scenes and actions, it leads to the challenge that plot information is not stated explicitly but rather only implied in the dialogue. For example, the transcript in Fig. 6.2 does not explicitly describe what Sheldon and Leonard are playing. However, it is implied by Sheldon when he mentions playing “Lord of the Rings Risk,” and later by Penny when she says that she does not “want to spend the whole day playing a board game.”
A related challenge is the need to understand the context in which characters’ utterances are situated. In the example, the recap describes four characters taking sides regarding playing a board game. The transcript expresses the characters’ sentiments through their interactions with one another. The conflict does not occur until Sheldon proposes to “stay here and play Lord of the Rings Risk”, and it becomes more apparent when Penny mentions she does not want to play the board game. Given the context, Leonard’s series of yes and no responses to Penny’s questions is largely due to the awkward situation, and it actually shows that he is happy playing the game as he and Sheldon are doing so at the beginning of the scene. Similarly, Amy

mentions their previous agreement with Sheldon as a way of politely declining Sheldon’s plan. The sentiments of characters are not necessarily easily discernible from their utterances but rather must be inferred using context and knowledge about the characters.
Another challenge in SUMMSCREEN is the need to draw information from a wide range of the input transcripts, which arises for two primary reasons. First, there are many utterances that serve a purpose other than driving the plot forward. They may help to develop characters or character relationships, or to add humor or suspense. These lines enrich the narrative but their information content is often omitted from the summaries. For example, in the first instance in Fig. 6.4, we show key lines from the transcript that pertain to the excerpt of the summary. There are many other lines between the lines shown, which are conversations between the doctor and other characters. This property necessitates the models’ ability to correctly attend to major events across the transcript when generating summaries. The pattern can also be observed in Table 6.13 through the differences between the number of unique characters in recaps and transcripts. More than half of the characters in the transcripts are not contained in the recaps.
The second reason why information needs to be combined across wide ranges of the input relates to scene breaks and multiple plots. As a TV show often narrates a few plots in parallel, scene breaks are used to separate the stories. The discontinuity sometimes requires models to connect subplots hundreds of lines apart. For example, for the second instance in Fig. 6.4, the show uses scene breaks to express what is happening when Cullen Bohannon escapes from the Swede, which is why there are almost two hundred lines between Cullen Bohannon’s escape and his appearance at Durant’s office.
6.2.4 Method
In this section, we describe modeling approaches that we benchmark on SUMMSCREEN. We note that since the meaning of sentences in transcripts is highly contextdependent, extractive summarization approaches are not expected to be useful for this dataset. We report the results from nearest neighbor-based extractive summarizers mostly for characterizing the dataset.
Neural Models. We use transformer based sequence-to-sequence architectures (Vaswani et al., 2017). Because transcripts are quite long, we limit the number of encoder hidden vectors that are used in the decoder’s attention mechanism. To do so, when encoding transcripts, we first append a special token [EOS] to each line of the transcript, and then linearize the transcript. We then only feed the vectors representing these special tokens to the decoder. We use the Longformer (Beltagy et al., 2020) as our encoder architecture, and set the [EOS] tokens to use global attention. For our decoders, we use the standard transformer architecture.
Nearest Neighbor Models (NNMs). We consider two metrics when finding nearest neighbors: BM25 (Robertson et al., 1995; a popular metric for information retrieval), and ROUGE scores. We use ROUGE scores as they are used for evaluation, and we use BM25 because it is designed for retrieving long documents whereas ROUGE scores are not. When using ROUGE scores, we use the average of ROUGE1, ROUGE-2, and ROUGE-L. We consider three types of nearest neighbor search: transcript-to-transcript, recap-to-transcript, and recap-to-recap.
Recap-to-transcript (NNM-r2t). We use each sentence in the recap as queries and the lines in the corresponding transcript as candidates. The generation is formed by the nearest neighbors for each sentence. We use BM25 or ROUGE scores as the metric. This method can serve as an oracle result for an extractive summarization system, showing roughly how much information can be extracted at the utterance level from the source transcript.
Transcript-to-transcript (NNM-t2t). We use the transcripts in the test sets as queries, the transcripts in the training sets as candidates, and then find the nearest neighbors using BM25. The generations are the corresponding recaps. his baseline measures the similarity of instances between training and test splits.
Recap-to-recap (NNM-r2r). This setting is similar to the “transcript-to-transcript” setting, but we use recaps for both queries and candidates, and we use ROUGE and our proposed entity-centric scores (see Section 6.2.5 for more details) as the metric. When using the entity metrics, we use the average of the 4 metric scores. This is an oracle baseline of the “transcript-to-transcript” setting and also measures the similarity of the splits.
Hybrid Models. As content selection has been shown to be helpful in prior work (Gehrmann et al., 2018; Liu* et al., 2018), we use the “recap-to-transcript” nearest neighbor model and BM25 as the metric to select the most salient content from transcripts, and then apply neural models to the selected content when performing generation. As these methods combine nearest neighbor models and neural models, we refer to them as hybrid models.
In particular, for each sentence in the recap, we find the top three most similar lines in the transcript, include two extra lines that come before or after the selected lines as context, and also include a line that is retrieved by using the whole recap. As the selected content is significantly shorter than the original transcript, it allows us to use pretrained models.[17] Therefore, in this setting, we fine-tune a pretrained BART-large model (Lewis et al., 2020b). We note that as the nearest neighbor models rely on the gold standard recaps, this hybrid model demonstrates an approximate upper bound on performance when using powerful content selectors.[18]
To establish a non-oracle baseline, we train neural models to predict the selected lines, and then fine-tune BART-large models on the predicted lines. Details of the architecture for this component, which we call our “neural content selector”, are as follows. We use a 3-layer longformer encoder followed by a 2-layer feedforward network with GELU activations Hendrycks and Gimpel (2016). We perform early stopping based on F1 scores on the development sets, where the threshold is chosen by averaging over the oracle thresholds for each instance. When selecting content, we use the threshold chosen based on the development set and ensure that no less than 10% of lines for each transcript are selected. The model achieves test performance (F1 scores) of 19.0 on FD, 19.2 on anonymized FD, 41.5 on TMS, and 40.1 on anonymized TMS.
6.2.5 Experiments
Experimental Setup. We report BLEU, ROUGE-1 (R1), ROUGE-2 (R2), and ROUGE-L (RL). We report the average of these four metrics as it generally shows the semantic similarities between generations and references. We will refer to these metrics as generic metrics as they treat each word equally.
As characters are fundamental to TV show plots, we believe the quality of plot summaries also depends on including the right characters. To take this factor into account, we compute several bag of character (BoC) metrics based on the fraction of the overlapping characters between generated and gold standard recaps. Formally, we define the BoC precision to be
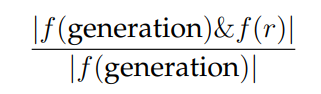
here f is a function that extracts the bag of characters from some text, where we perform string matching based on the character names that are automatically extracted during dataset construction (see Section 6.2.3), & computes the intersection of two bags, | · | returns the size of its inputs, and r is the gold standard recap. Similarly, we define the BoC recall to be
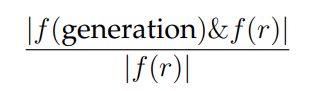
Since BoC does not consider relations between characters, we also report bag of character relations (BoR) metrics based on the cooccurrence of character pairs. We assume two characters are related when they appear in the same sentence. After obtaining the character relations from the gold standard recaps and the generations, we compute recall and precision against the recaps following the same approach as BoC. We note that the extracted relations are non-directional, and BoR does not consider frequency of the cooccurrences. We also report the averages of both precisions and recalls from both the BoC and BoR metrics. Code and the dataset are available at https://github.com/mingdachen/SummScreen.
Hyperparameters. We set the maximum sequence length to be 14336 for the encoder and 1024 for the decoder. We use byte-pair encoding Sennrich et al. (2016) with approximately 10k vocabulary size. We use a 1-layer encoder and a 12-layer decoder with 1024 hidden units unless otherwise specified. We use an effective batch size of 200, and train the models for 50 epochs. During training, we perform early stopping on the development sets based on perplexities. During testing, we use beam search with trigram blocking Paulus et al. (2018) and a beam size of 5.
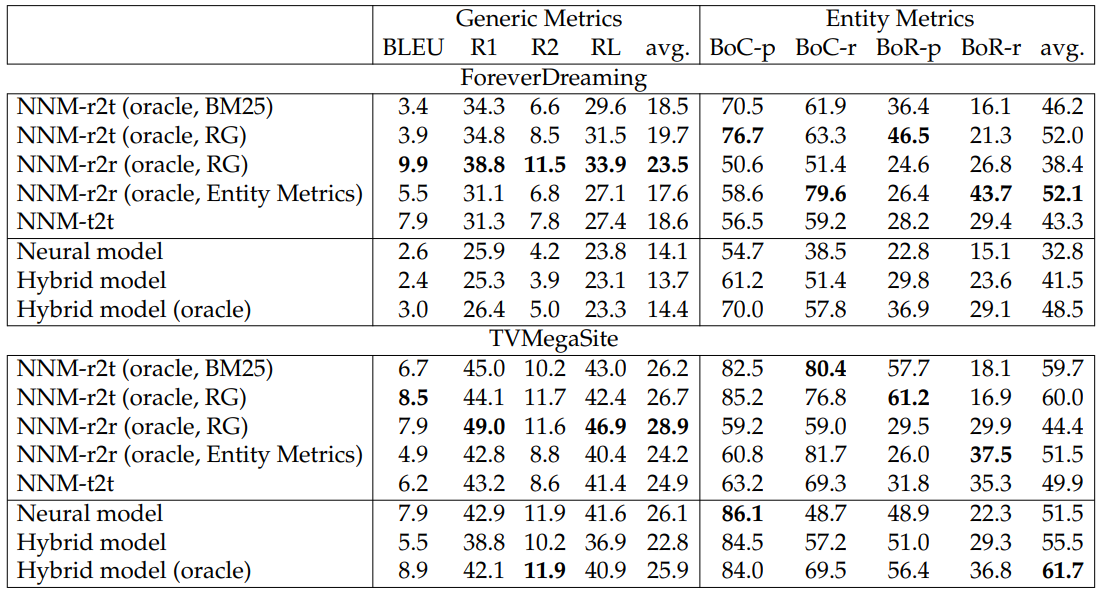
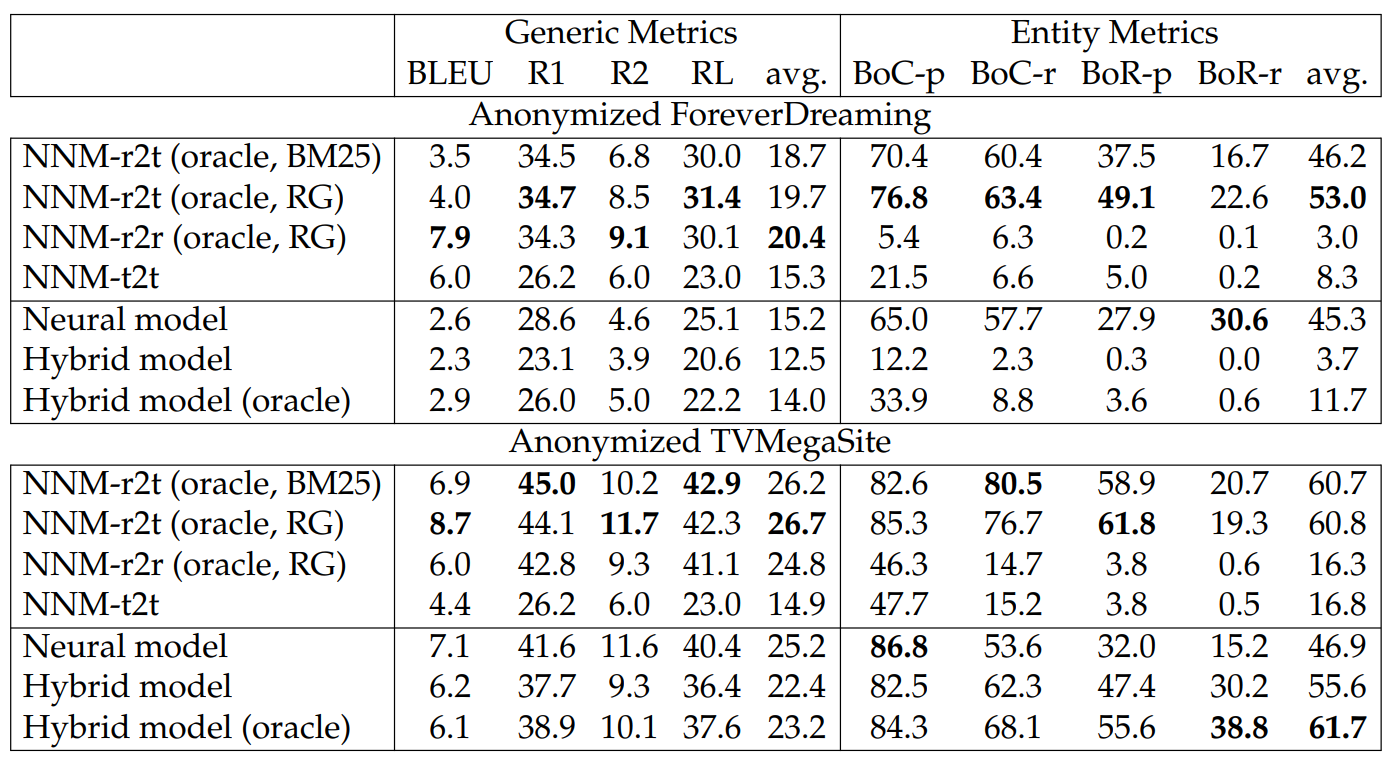
Experimental Results. We report test results for FD and TMS in Table 6.16. Our findings for the nearest neighbor models are as follows:
1. We find that the nearest neighbor models give strong performance on our dataset. In particular, NNM-r2t shows the best performance in general. This demonstrates that there is still room for improving the ability of our neural models to extract the most useful information from transcripts, suggesting that improved transcript modeling may be a fruitful research direction for these datasets.
2. We observe that NNM-r2r exhibits different strengths when based on different metrics, for example, using ROUGE scores will lead to results favorable to generic metrics.
As for the results involving neural models, our findings are as follows:
-
The neural model shows strong performance in generic semantic matching but it is relatively weak in entity metrics compared to the non-oracle baselines.
-
The hybrid model is better than the neural model in terms of generating character mentions and relations. With the help of the oracle content selector, the hybrid model improves significantly in both semantic matching and entity-related metrics, showing that future research may find improvement by designing better content selectors.
6.2.6 Analysis
Anonymized SUMMSCREEN. As plots for TV shows are typically about a limited number of characters, models trained on SUMMSCREEN may focus on those characters and their typical behaviors rather than the actual actions taking place in the input transcripts. To eliminate this effect, we create an anonymized version of SUMMSCREEN by replacing character names with random character IDs. We ensure that the IDs of particular characters in different episodes are randomly assigned (i.e., IDs are not consistent across episodes).
Fig. 6.5 shows an example from anonymized SUMMSCREEN. Anonymized question answering datasets have also been created out of similar concerns to those just described (Hermann et al., 2015).
Results for Anonymized SUMMSCREEN. In Table 6.17, it is interesting to observe the performance differences of the nearest neighbor models between the anonymized and non-anonymized datasets. The gaps show that the anonymization does not lead to much difference regarding the similarities between recaps and

transcripts, but it makes correlations among recaps and transcripts much weaker especially for those entities.
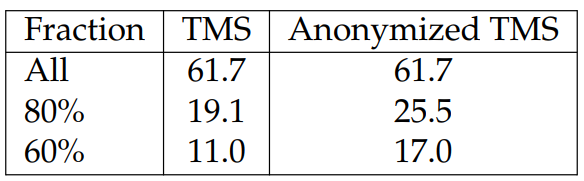
Effect of Anonymization. We study the effect of anonymization by investigating performance on rare entities. To do so, we first compute entity frequencies for each TV show from the training set, rank the entities by their frequencies, pick the rare entities according to the rank, and evaluate performance for the selected entities. We summarize the results in Table 6.18. We find that models trained on the anonymized TMS dataset give better performance on rare entities, suggesting that anonymization helps in modeling rare entities. The fact that the two models have the same performance in the “all” setting shows that anonymization also makes the learning of common entities harder, matching our expectations.
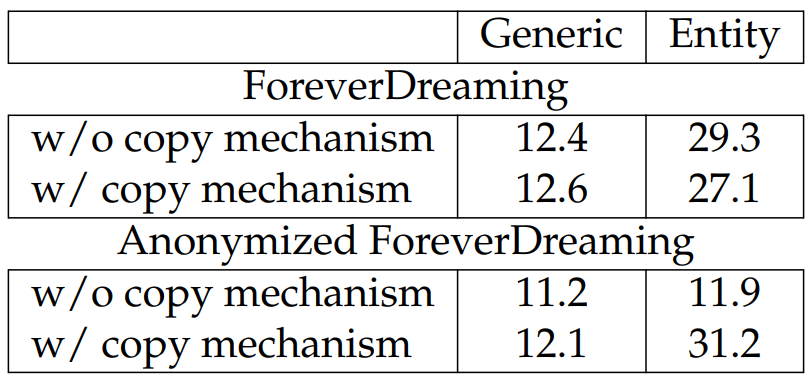
Effect of Copy Mechanism. We report results on ForeverDreaming in Table 6.19 comparing models with and without the copy mechanism. We note that models used in this table use 6-layer decoders with 512 hidden units, so the results are not directly comparable to other results. From the results in Table 6.19, we find that the copy mechanism helps tremendously on the anonymized dataset, but gives mixed results on the non-anonymized dataset. This is likely due to the fact that for the anonymized dataset, there is not enough training data for the character ID embeddings, and the copy mechanism helps to reduce the required supervision. While there may be better ways of handling the character IDs that may avoid this issue (e.g., sampling IDs from exponential-like distributions rather than uniform distribution), we leave this for future research.
However, this benefit does not hold for the non-anonymized dataset as the models are able to exploit more information when learning character name embeddings by having access to the character names.
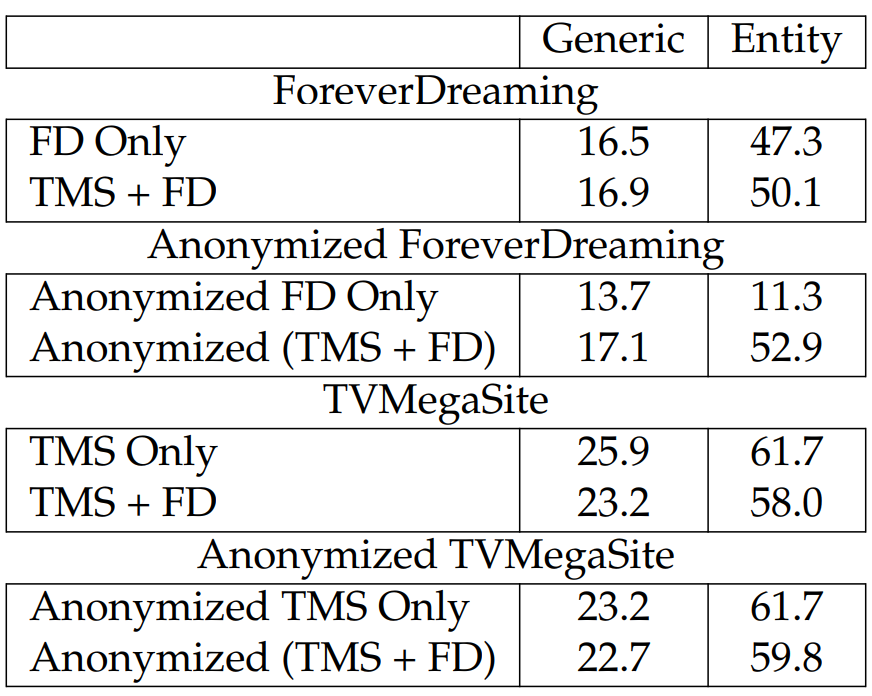
Effect of Combining FD and TMS. We study the effect of transfer learning using these two resources. When doing so, we use the training and development sets constructed from both resources, and at test time, we evaluate models on the official test splits. We experiment with the oracle hybrid model and report results in Table 6.20. In general, we find that extra training data helps FD. We hypothesize that this is due to the relatively small size of FD. However, for TMS, training on FD harms performance, which is likely because of the larger training set size for TMS and the differences between the two resources. It is interesting to see that the anonymized ForeverDreaming benefits greatly from additional training data, supporting our previous hypothesis that the copy mechanism helps to reduce the amount of required supervision.
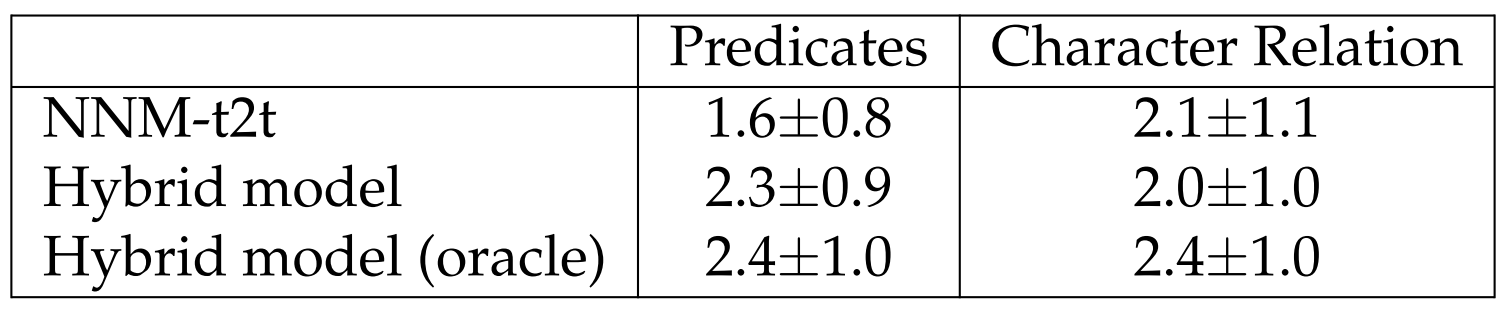
Human Evaluation. We conduct human evaluations for three models: NNM-t2t, hybrid model, and hybrid model (oracle). To evaluate two key aspects of SUMMSCREEN, namely events and characters relationships, we ask human annotators two questions. The first is “Do the predicates in the generation match the predicates in the reference?”[19] The second is “When multiple characters are mentioned as being related in some way in the generated recap, are those same characters mentioned as being related in some way in the reference?” We disregard the subjects in the first question because the second question involves evaluating characters and we want the two questions to focus on different aspects to maximize the efficiency of human annotations. Ratings are on a 1-5 scale with 5 indicating a perfect match. We randomly picked instances from the FD test set. We (the authors) annotated 120 instances in total for each question.
After dropping 2 invalid annotations for the second question (as there may not be multiple characters mentioned), we summarize results in Table 6.21. While trends for the model performance on character relations are generally similar to our observations in Table 6.16, the results for predicate match are very different for NNM-t2t. This is likely because the first question is about predicates disregarding the correctness of the participants. We also want to highlight that compared to the oracle hybrid model, the non-oracle one shows competitive performance on predicate match but is less close in terms of generating correct character relations, showing future opportunities for improving this model.

Generation Samples. In Table 6.22, we show generation samples for the following models: the neural model, the hybrid model, and the oracle hybrid model. The neural model manages to fit most of the character names from the reference into the generation. The generation shares similar topics with the reference, but compared to the hybrid models it lacks specifics. This matches our observations from the automatics metrics where the neural model performs better on the generic metrics but worse on the entity metrics on the non-anonymized datasets. We hypothesize that this is caused by the difficulty of modeling long-form text.
In the output of the non-oracle hybrid model, many facts that are not mentioned in the reference are actually from the transcript. For example, “40-year-old woman” and “de-fleshed prior to her death” are in the transcript. Despite containing many specifics, the generation misses a few important details, such as the absence of mentioning main characters involved (i.e., Brennan and Booth). It also has incorrect facts. For example, according to the transcript, there are rocks at the scene, but the model describes the setting as a rock quarry. Compared to the other three models, the generation from the oracle hybrid model is the most faithful, although there are still incorrect facts (e.g., “... and they are having a hard time adjusting to their new life in the city.”). The differences between the oracle and non-oracle hybrid model suggest that future research can focus on improving models’ capabilities of doing content selection. As both oracle and non-oracle hybrid models suffer from generating incorrect facts, faithfulness in generation is also an important future research direction.
This paper is available on arxiv under CC 4.0 license.
[11] http://tvmegasite.net/
[12] transcripts.foreverdreaming.org
[13] www.tvmaze.com, an online TV database curated by TV fans
[14] The genre information is from TVMaze where a TV show may correspond to multiple genres.
[15] We use the named entity recognizer from spaCy.
[16] For this reason, we do not include their statistics in Table 6.15.
[17] After the selection steps, the average number of tokens of the transcripts for FD and TMS reduces to 1138.9 and 3252.7 respectively.
[18] We use the maximum sequence length of 1024 (i.e., we truncate the input sequences if they are longer than 1024) for BART-large due to computational constraints.
[19] By “predicate” here we mean the part of a sentence or clause containing a verb and stating something about the subject (e.g., “went home” in “John went home”).